How to create sound from electricity? How does it work in a synthesizer? And how is a rich variety of sounds created by synthesis? Here is some general information on how we can hear electricity and how sound synthesis creates something we would have never been able to hear without it.
What sound and electricity have in common
Sound has a wave nature. When we hear sounds, our eardrums undergo the smallest changes in pressure. However, we do not hear all the vibrations. Our hearing ability is limited to a frequency range of approximately 20 to 20,000 Hz.
The vibration of the air we hear can be graphically depicted as follows.
The loudness of the sound is determined by the amplitude – the greater the difference between low and high pressure, the louder the sound. And the pitch is expressed in the frequency of the pressure change.

The alternating electric current can also be thought of as a wave. Only instead of pressure, it is its voltage that changes. Inventors working on sound recording methods decided that it would be very convenient to convert acoustic pressure fluctuations into electrical voltage fluctuations.
And it can work perfectly well the other way round: the alternating voltage on the coil in the magnetic field of permanent magnets vibrates the membrane and creates air vibrations. And we can hear these vibrations. This is the general principle of operation of the well-known drivers installed in our loudspeakers.
Make electricity sound
But what if we do not record and play the recorded sound, but create it ourselves from scratch. After all, you can just take an alternator, connect it to the speaker and voila.
Certainly we will hear a sound (providing that the frequency is generated within the audible range), but it is highly unlikely to be pleasant. Natural sounds are characterized by harmonic complexity and variability. And the generated wave is nothing but a sustainable noise throughout eternity. And that is exactly what we call a synthesized sound.
To create more musical sounds, we need to change amplitude and its frequency. It can be done in a great many ways by changing these parameters at different speeds and intervals. And each will lead to a different audible result.
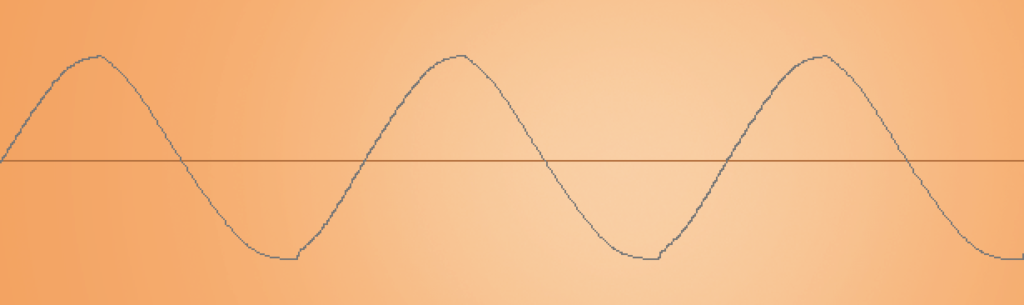
Let’s get back to our generator. With its help we can create different waveforms. It means we can already influence the rate of amplitude change without changing the frequency. There are several basic types of generated waves:




And they all sound different at the same frequency. Because they create a different number of harmonic fluctuations. It becomes evident when you look at the spectrogram of each of these shapes:

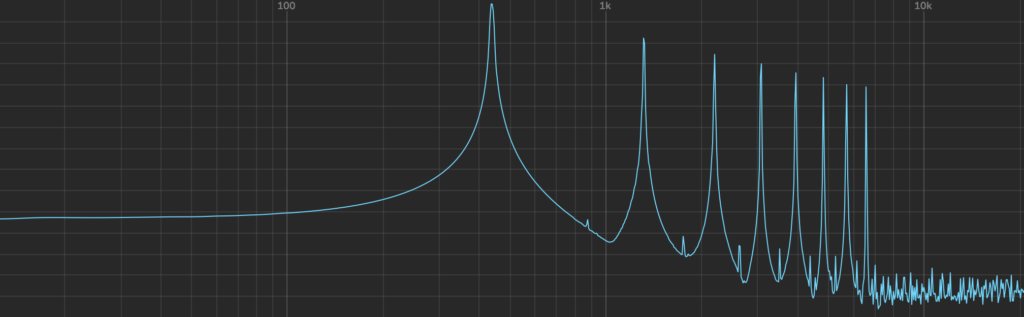


To create even more harmoniously complex timbres, we can use various methods of sound synthesis.
The most common and simplest method is subtractive synthesis. It is called so because we try to achieve the required timbre by subtracting frequencies from a complex wave saturated with a large number of harmonic vibrations. For example, from a sawtooth or square wave. It is done by using filters that only pass a certain frequency range through themselves.
The opposite is additive synthesis, when simple waves of different frequencies with the least amount of harmonic oscillations, most often sinusoids, are added to achieve the required timbre.
I will not go into details of synthesis methods now. If interested you will find them explained clearly and thoroughly here.
Sound wave processing
Wow, we’ve got some sound! Now let’s add some dynamics. Indeed, in music, there is only one thing more important than notes – pauses.
As you play a musical instrument, dynamics can vary a lot. For instance, when we press a piano key, the sound starts abruptly and smoothly fades away. And if we begin to move the bow along the violin string, we will hear a sound with a gradually increasing volume.
It is customary to distinguish four dynamic phases of any sound – attack, decay, sustain and release. Abbreviated to ADSR.

Attack determines the timing a note sounds at maximum volume; decay indicates the timing the volume goes from its maximum to the sustain level; release shows how quickly the volume falls to zero when you stop pressing the key. Of these four parameters, only sustain indicates the level (not the timing!) at which a note sounds when the key is held down.
Acoustic instruments, due to their complex timbre, have a natural beauty of sound. The performer can change the dynamic parameters of the notes played and even affect the timbre of the sound.
ADSR parameters can help you achieve a similar effect with a synthesized sound, so that it wouldn’t be too artificial and mechanical as if you were merely pressing the on/off button. In synthesizers, the devices that set these changes are called envelope generators.
Sound synthesis allows us to influence not only the volume, but also all the other parameters, in contrast to acoustic instruments. With the help of envelope, you can change the waveform, its frequency, control the parameters of filters or sound processing effects. Anything. Absolutely. Any whim. Therefore, you can create an acoustic variety which is difficult to imagine in real life.
Moreover, you can simultaneously use several different control signal generators. And it doesn’t have to be ADSR generators only. If you want to change some parameters periodically with a certain frequency, you can take the very generator you created the sound with, and change the required parameter with its signal with a particular frequency.
Someone does not need such a wide range of opportunities to experiment with sound and they leave it at the discretion of the creators of synthesizers, as I have already told you in the previous article. It seems to me that you should not deprive yourself of this opportunity. This flexibility is the main advantage of modular synthesizers. That is why sound synthesis is so wonderful – boundless imagination and no frames.